众所周知,一直以来嵌入都是非常受欢迎的,原因是什么呢?接下来,就让我们从相关背景中窥探一二。所有机器学习模型都要求输入数据是数字。不幸的是,实际中的数据都是数值和分类值的混合(考虑结构化数据)。
分类数据的示例如下所示:
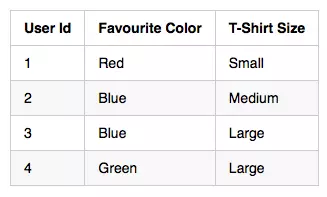

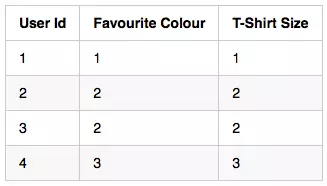
原始数据
其中,我们有两个分类变量(此处忽略用户Id),最喜欢的颜色(FC)和T恤大小(TS)。我们可以使用以下方法来表示我们的输入数据:
标签编码(Label Encoding)
将FC表示为整数值是不正确的。为什么呢?如果我把red相加两次(1 + 1),它的相加结果会是blue(2)吗?不,这是没有意义的,这样做,只会将有关这个变量的完整信息稀释掉。
将TS表示为数值也是不正确的。为什么呢?如果我将all和medium相加(1 + 2),它的相加结果会是large(3)吗?不,再次这样做将会导致丢失关于这个变量的信息。
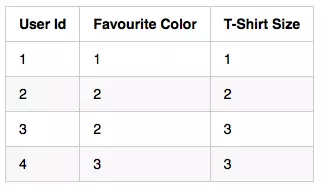
标签编码
独热编码(One Hot Encoding)
使用独热编码可能算是一个更好的注意。它是一种将分类数据表示为稀疏向量的简单方法。 例如下面的这个示例:
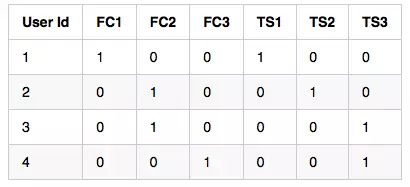
独热编码
用独热编码来表示FC是一个好主意。我们将Red表示为{1,0,0},Blue表示为{0,1,0},Green表示为{0,0,1}。这意味着每个等级(Red、Green和Blue)彼此之间距离相等。
但是用同样的方式来表示TS并不是一个好主意,我们都知道,all<medium<large。如果这样做的话,订购信息将会丢失。这个变量中的所有等级都被处理为彼此之间距离相等。另外,如果我们有1000个等级而不是3个,将会发生什么呢?这将使我们的矩阵大而稀疏。
嵌入(Embedding)
可以说,我们想用将具有三个等级的输入变量表示为二维数据。使用嵌入层,底层自微分引擎(the underlaying automatic differentiation engines,例如Tensorflow或PyTorch)将具有三个等级的输入数据减少为二维数据。
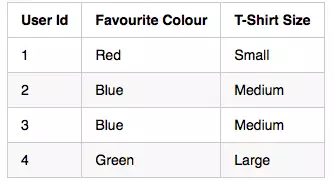
输入数据
用标签编码表示输入数据
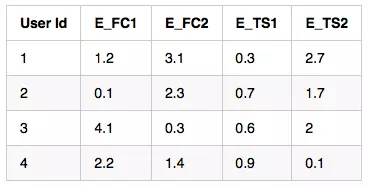
嵌入式数据
输入数据需要用索引表示。这一点可以通过标签编码轻松实现。这是你的嵌入层的输入。
最初,权重是随机初始化的,它们使用随机梯度下降得到优化,从而在二维空间中获得良好的数据表示。可以说,当我们有100个等级时,并且想要在50个维度中获得这个数据的表示时,这是一个非常有用的主意。
罗斯曼挑战赛
这个策略已经被很多Kaggle参赛者使用,用以使得他们的分类数据集能够获得好的表示。(提出此想法的队伍在本次比赛中排名第三)。
你可以观察到,在对输入数据进行一次独热编码之后,他们将其嵌入到来自不同分类变量的较低维度中。
这些嵌入的输出被连接并馈送到两层神经网络中。
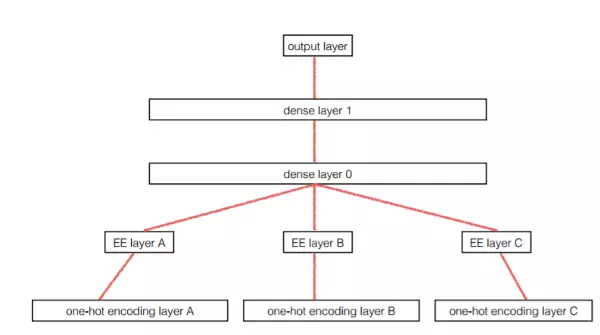
变量状态的嵌入表示
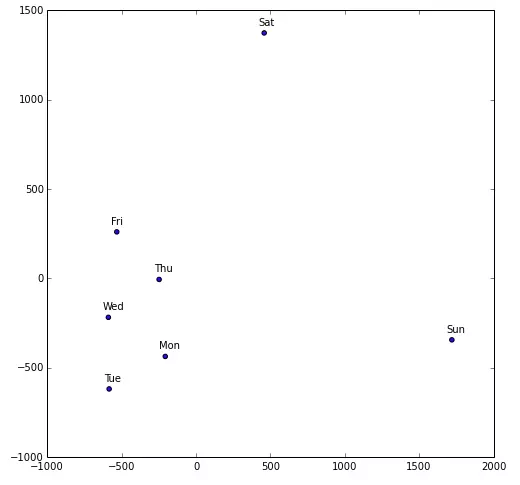
周变量的嵌入表示
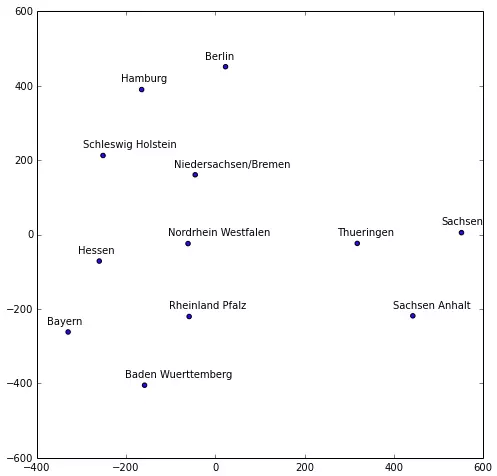
从上面我们可以看到,在二维环境下,周变量的嵌入表示。
令人惊讶的是,嵌入是如何设法找出周末的销售与工作日的销售之间的不同的。
状态变量的嵌入表示几乎等同于世界地图上的实际表示。
图:unsplash
原文来源:arxiv
作者:Krishna
「雷克世界」编译:嗯~阿童木呀